
Syncing skills, rules and subagents across repos with amgr
If you’ve spent any real time with agentic tools, you’ve felt this: rules, skills, and configs scattered across half a dozen projects with no real linkage. You spin up a new repo and immediately face the same boring questions: where’s my base rule set, what’s the right boilerplate, which tools need which files?
Even with the ecosystem moving in the right direction, the core problem doesn’t go away. Tools like Vercel’s skills.sh help with what an agent can do, but not how you bootstrap a new project, or how you keep different kinds of rules in sync across personal, work, writing, and side projects.
Last week I ran into it again. I was setting up another repo and caught myself copying the same Cursor rules and docs guidelines I’ve already pasted into three or four other places. It wasn’t hard - just dumb. And it never ends.
That’s when the question finally landed:
why am I rebuilding the same agent setup every time I start a new project?
I wanted one source of truth: write once, use everywhere. I couldn’t find a sane way to do it - so I built one.
The Problem: One Brain, Many Contexts
The mess isn’t just file formats. It’s that I need different agent setups for different kinds of work, and I’m doing that across a pile of repos.
Backend repo: heavy coding rules, test commands, debugging skills. Frontend repo: UI patterns, different MCP servers. Writing repo: tone and structure, zero coding noise.
I can build these setups manually, but it doesn’t scale. If I tweak my base rules, I have to remember which repos should inherit it and which ones shouldn’t. If I add a new “writing voice,” I have to thread it through the right places without leaking into code projects.
So the real pain is this: I want one source of truth, but I need selective deployment.
That’s the hole amgr (agents manager) is trying to fill.
The Idea: One Rules Repo, Selective Sync
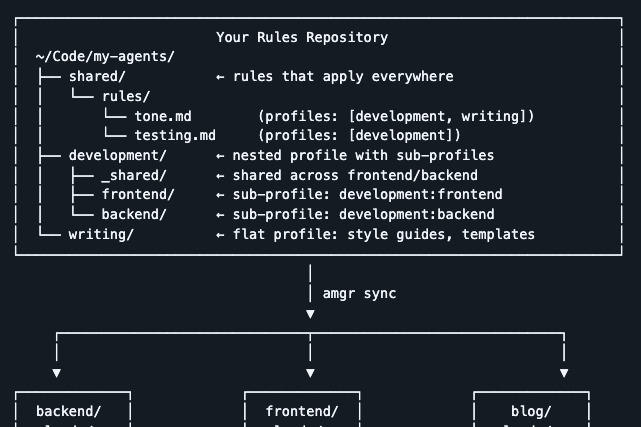
amgr’s mental model is simple: keep a single “rules repo” that holds your agent brain, then sync only the parts each project actually needs.
In practice, that looks like a repo with:
- shared/ - rules that should apply everywhere
- development/ - a nested profile, with sub‑profiles like
frontend/andbackend/ - writing/ - a flat profile for tone, templates, and docs
- (and any other profile you might want)
Then each project gets a tiny .amgr/config.json that says: which tools, which features, and which profiles to pull in.
You write once. You sync everywhere. And the right rules land in the right repos without manual glue.
Examples: one repo, selective sync
So what does that look like in practice? Here’s the short version.
amgr uses a rules repo: one repository where your agent configs live (rules, skills, subagents, commands). You don’t copy files between projects anymore. You sync slices.
Create one like this:
mkdir ~/Code/my-agents && cd ~/Code/my-agents
amgr repo init --name "my-agents"
Then I split it into profiles (think: contexts):
amgr repo add development --description "Coding and debugging"
amgr repo add writing --description "Documentation and content"
Now the repo has a home for shared rules, and separate buckets for dev vs writing. Mine ends up looking like this:
~/Code/my-agents/
├── shared/
│ └── rules/
│ └── tone.md # applies everywhere
├── development/
│ ├── _shared/
│ │ └── rules/
│ │ └── testing.md # shared across dev sub‑profiles
│ ├── backend/
│ │ └── agents/
│ │ └── db-tuner.md # a subagent for database work
│ └── frontend/
│ └── skills/
│ └── ui-checker/ # a skill for UI reviews
│ └── SKILL.md
└── writing/
└── rules/
└── voice.md # writing voice + style
Now the fun part: each repo only pulls what it needs.
Example 1: backend repo (dev:backend)
.amgr/config.json:
{
"targets": ["claudecode", "cursor"],
"profiles": ["shared", "development:backend"]
}
amgr sync brings in:
shared/rules/tone.mddevelopment/_shared/rules/testing.mddevelopment/backend/agents/db-tuner.md
No frontend UI skills. No writing voice.
Example 2: writing repo (writing)
.amgr/config.json:
{
"targets": ["claudecode"],
"profiles": ["shared", "writing"]
}
Now you get:
shared/rules/tone.mdwriting/rules/voice.md
No coding rules. No dev subagents. Clean writing context only.
Example 3: frontend repo (dev:frontend)
.amgr/config.json:
{
"targets": ["opencode", "cursor"],
"profiles": ["shared", "development:frontend"]
}
You get the shared rules, the dev‑shared testing rules, and the ui-checker skill - but none of the backend‑only subagents.
That’s the trick. One repo. Many profiles. Each project gets the right slice.
Why this matters (and why now)
The ecosystem is moving. As I mentioned, Vercel recently shipped the skills CLI and skills.sh directory, and that’s a big deal. It makes skills shareable and discoverable across tools.
But skills solve only one part of the problem: the “what can my agent do?” question. The daily pain is still “how do I spin up a new project with the right brain and keep it in sync?” That’s where a rules repo + selective sync matters.
If this stuff becomes native across tools, amgr should disappear. Until then, I want one source of truth and a clean way to slice it per project.
FIN