
As every privacy-aware internet user is well aware, in recent years the internet became a living example of the well known phrase “if something’s free - you’re the product”.
These days, many digital services that we use and rely upon are paying their employees by mining and selling the new gold - users’ data, data that is being sold to third-party ad companies, who then make their money by allowing companies to target specific portions of the population with their ads.
But this market is currently undergoing a major shift, with the deprecation of old tracking methods and the rise of new ones. In this post, I would like to dive into a new tracking technology that recently made some buzz in the tech community, and explore the problems it tries to solve.
User Tracking
While tracking users and selling their data (or rather, their metadata - habits, interests and so on) is the way many of the key players in the internet landscape make their money, I think that the most prominent examples of this behavior are Google and Facebook. Let’s take a look at what Facebook has to offer for any potential product maker who wants to get his product to the hands of willing customers:
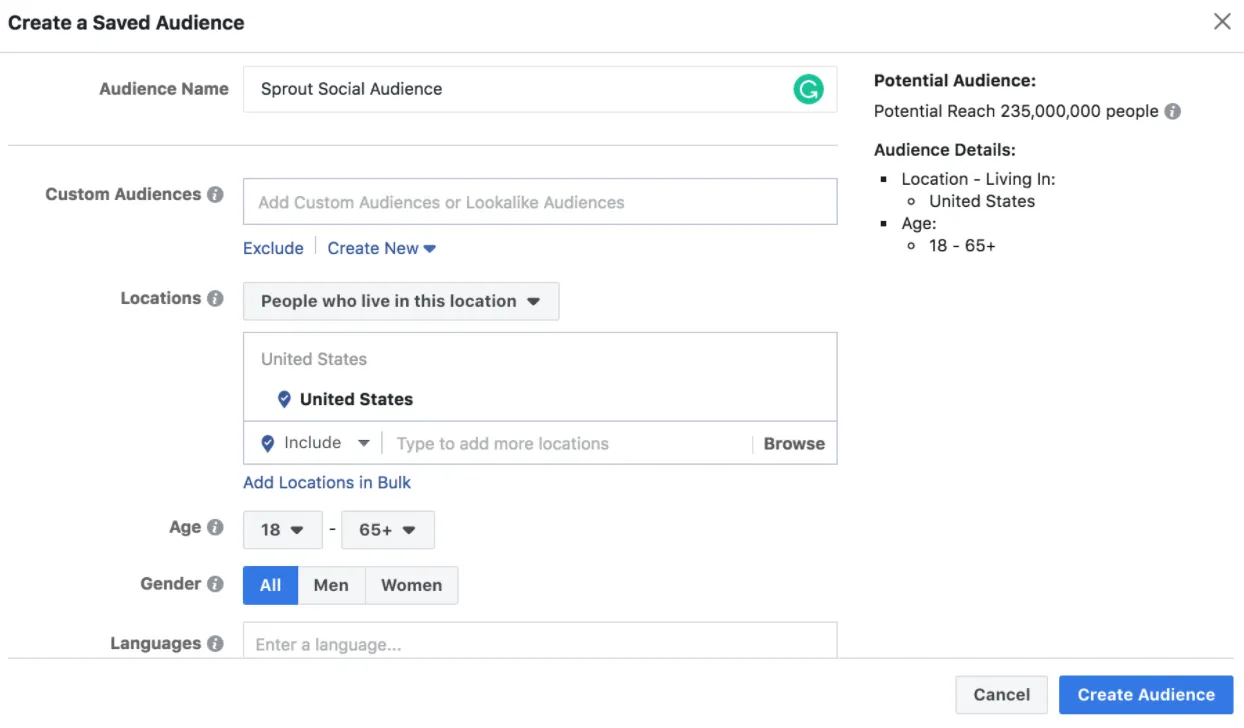
Seems pretty reasonable, right? Allowing advertisers to target people from specific countries isn’t very privacy violating, and the same goes for age information - especially given the fact that this is all information that Facebook already have by choice - most users will let Facebook have these data points without a second thought, and it’s not any kind of tracking.
Ok. What about these options?
But wait - how can Facebook know which websites the current user has been visiting? Unlike the previous example, this information shouldn’t be in Facebook’s hands!
To understand how this information reaches the likes of Facebook, let’s take a look at the underlaying technology that enables this sort of tracking - Cookies.
Cookies

The current method most websites use to track users across the vest regions of the internet are cutely named “cookies”. The idea is simple - whenever you visit a website, you issue an HTTP request for the server’s content. In its response, alongside the actual content, the sever can set a header called Set-Cookie which asks the client’s browser to save a tiny, unique piece of information and associate it with the current website (more on that last sentence in a bit):

Once set, the client will use this cookie on every subsequent request to the server, allowing the server to retain the session’s state over the otherwise stateless HTTP protocol.
But wait, you might say. If cookies are only associated with the current website, how can it be used for tracking?
Third-Party Cookies
As I said, normally cookies are set for the current website (in this context, we will define “current website” as the site pointed to by the browser’s address bar) and therefor are limited in their effect on the user. However, these days most - if not all - sites load content from external sources - and if your browser is reaching out to external servers to fetch these external resources, what stops those servers from serving your browser their cookies? Nothing.
From Wikipedia:
As an example, suppose a user visits www.example.org. This website contains an advertisement from ad.foxytracking.com, which, when downloaded, sets a cookie belonging to the advertisement’s domain (ad.foxytracking.com).
Then, the user visits another website, www.foo.com, which also contains an advertisement from ad.foxytracking.com and sets a cookie belonging to that domain (ad.foxytracking.com).
Eventually, both of these cookies will be sent to the advertiser when loading their advertisements or visiting their website.
The advertiser can then use these cookies to build up a browsing history of the user across all the websites that have ads from this advertiser, through the use of the HTTP referrer header field.
These kind of cookies are referred to as “Third-party cookies” (as opposed to the cookies of the current website, which are called “First party cookies”). By planting their resources in websites across the web (a practice known as a tracking pixel), ad networks can build a profile of a person that is identifiable by his cookie - and then sell this information to advertisers.
The chain is simple - the advertiser pays for getting his ads seen and receives exposure, the website pays by placing the ad on its page and including a tracking pixel, and they receive their money from the ad network who gets paid for matching specific users with targeted ads. Everyone wins, right?
Well, almost everyone. While it can be argued (and almost everyone who works in the advertisement industry will argue) that it is beneficial to the users to be receiving targeted ads, using this kind of targeted ads, ones that can target specific users, has been proven to be potentially harmful to users - with dangers ranging from racists using targeted ads to distribute hate speech, and going all the way to cyber security researchers being targeted by nation-state actors. Even worse - it can be used to play devilish pranks on your roommates!
This is a realization that most key players in the browser market have made way back. As a result, the current trend in the industry is to stop this practice by implementing browser-based solutions that will block third party cookies from being set. This includes announcements from Apple’s WebKit/Safari team, Mozilla’s Firefox, and even Google’s Chrome - which together consists of the majority of the browser makers market.
But while Mozilla - a non profit foundation - and Apple - which made a campaign about its stance on users’s privacy - can both prosper without ever making a cent from anything related to the advertisement business, Google have no such luxury.
In fact, Google makes most of its money from selling ads through the Google Ads network. So how can Google afford itself to prevent third party cookies - a move that will deal a severe blow to their main revenue source?
By offering an alternative, of course.
Federated Learning of Cohorts (FLoC)
In March, Google have announced that they will start “an online trial” (which is basically a washed-up term for A/B testing against Google Chrome’s user base) for a new technology called “Federated Learning of Cohorts”, or FLoC, for short.

The idea behind this technology is quite simple - instead of tracking specific users with a unique, per user identifier, Google aims to divide users into cohorts (another way of saying groups). These cohorts are used to group users with similar interests and browsing habits. Adtech companies (we will later define this term) can then use this information - the knowledge that a user of their site is a member of a given cohort to - to match users with products that are known to be liked by other members of the user’s cohort.
This way, Google says, each individual user’s privacy is being kept, as you can’t now use ads to target a specific person (as opposed to the current state, as illustrated by the roommate-prank example above).
Before we dive into my personal opinion of this technology, let’s take a look at how it is implemented - or rather, at how Google currently says it will be implemented, as this is only a proposed standard at this point in time.
How does FLoC work?
In order to understand how FLoC works, we will first need to understand a couple of basic terminology taken from Google’s proposal documentation:
- FLoC Service - A service used by the browser which creates a mathematical model aimed at assigning a given browser’s browsing habits (currently - browsing history) to a single cohort (represented by an integer). More on Google’s implementation in a bit.
- Browser - The user’s web browser. The browser uses the FLoC service’s algorithm in order to calculate which cohort is the closest to the browser’s browsing history. Note that the browser does not share information with the FLoC service - rather, it is using the algorithm provided by the service in order to calculate the cohort by itself.
- Advertiser - A company that pays to advertise its products.
- Publisher - A site that gets payed to display ads for advertisers.
- Adtech - A company that makes its money by getting linking customers that are interested in a specific advertiser’s products with publishers where these customers typically browse.
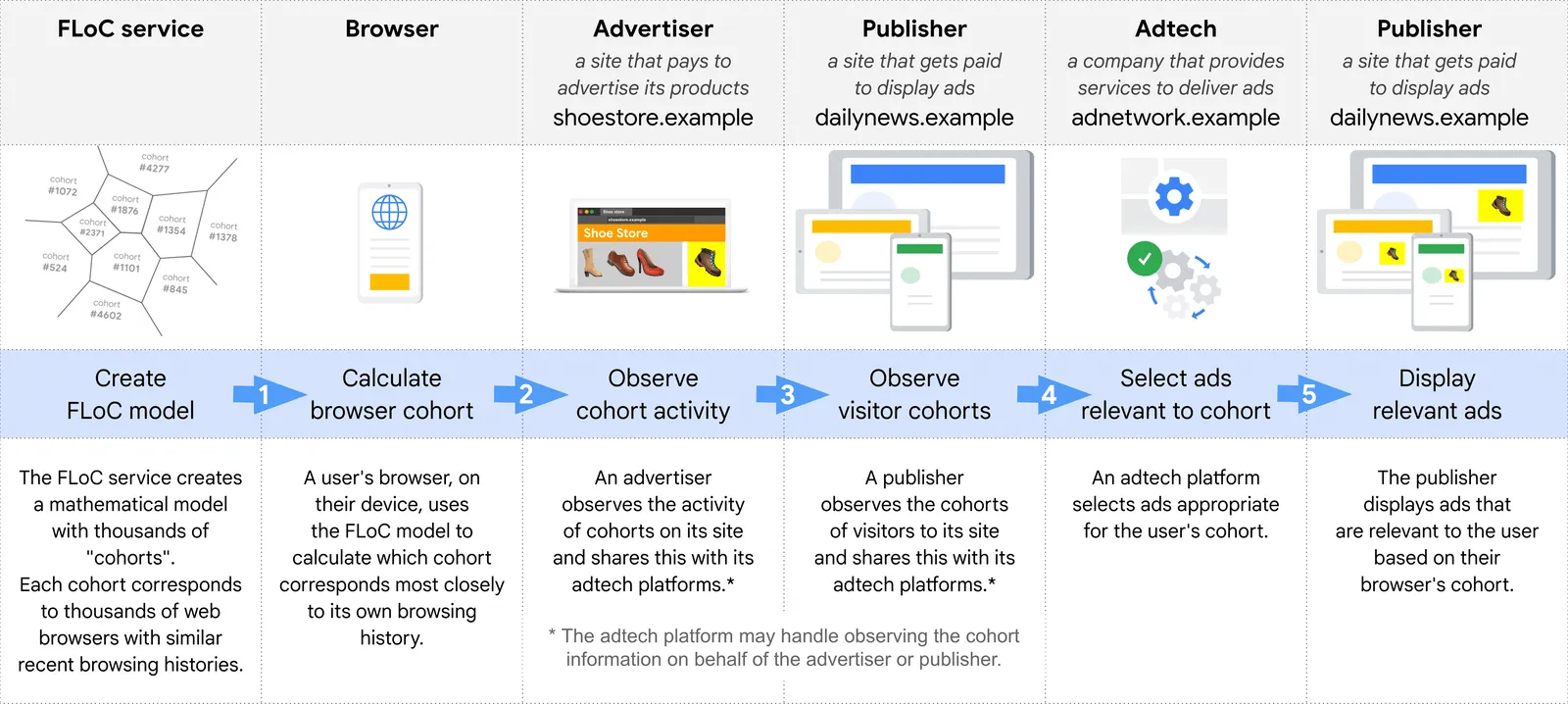
Let’s look at the example scenario from Google’s doc:
Yoshi visits shoestore.example.
The site asks Yoshi’s browser for its cohort: 1354.
Yoshi looks at hiking boots.
The site records that a browser from cohort 1354 showed interest in hiking boots.
The site later records additional interest in its products from cohort 1354, as well as from other cohorts.
Now it’s Alex’s turn.
Alex visits dailynews.example.
The site asks Alex’s browser for its cohort.
The site then makes a request for an ad to its adtech platform, adnetwork.example, including Alex’s browser’s cohort: 1354.
adnetwork.example can select an ad suitable for Alex by combining the data it has from the publisher dailynews.example and the advertiser shoestore.example:
Alex’s browser’s cohort (1354) provided by dailynews.example.
Data about cohorts and product interests from shoestore.example: “Browsers from cohort 1354 might be interested in hiking boots.”
adnetwork.example selects an ad appropriate to Alex: an ad for hiking boots on shoestore.example.
dailynews.example displays the ad 🥾.
According to Google, this is a prime example of the power of FLoC - while Yoshi’s personal details remain private, the ads can still be delivered in the same manner - or as Google puts it:
Don’t think of a cohort as a collection of people. Instead, think of a cohort as a grouping of browsing activity.
Cohort Algorithms
So let us do what Google asked us to, and think of cohort as a grouping of browsing activity. How does one efficiently and correctly group browsing histories? We all have very different web histories, and therefor one would think that the needed number of cohort will be almost endless - rendering it both ineffective for advertisers to gain any meaningful insight from and privacy harming for users who will find themself alone in a given cohort. We need a good system.
As per Google’s documentation, FLoC cohorts will never face this problem for a simple reason - it is not the problem that they wish to solve. Per Google, the FLoC service job isn’t to create an exact cohort for each browsing history timeline - its to “creates a multi-dimensional mathematical representation of all potential web browsing histories”.
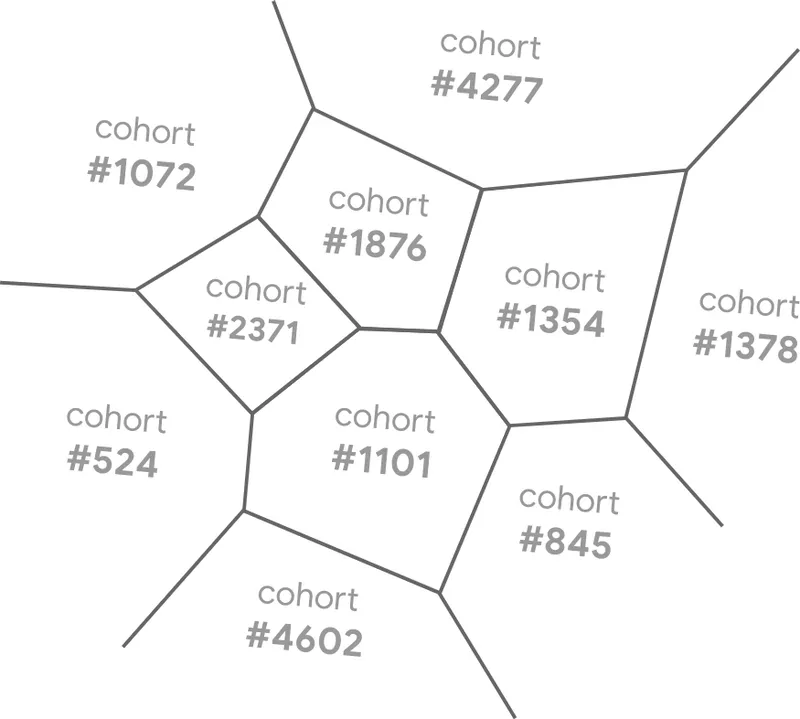
The idea is that this space is than segmented into a couple of thousands of regions, that represent a similar yet not exact browser history logs. Per Google:
Each segment represents a cluster of thousands of similar browsing histories. These groupings aren’t based on knowing any actual browsing histories; they’re simply based on picking random centers in “cohort space” or cutting up the space with random lines.
While Google has yet to formally announce which algorithm they will use, a white paper was published which stated that their current algorithm of choice is an algorithm called SimHash:
Simhashes are a clever means of rapidly finding near-identical documents (or other items) within a large corpus, without having to individually compare every document to every other document.
(Another good primer of SimHas can be found here)
Conclusion
Despite its seemingly innocent-looking documentation, I myself am not a big fan of this technology. While arguably better than the current state, this technology is still about finding new ways to continue tracking the users. As explained in great details in the EFF’s excellent paper about FLoC’s shortcomings:
FLoC is designed to prevent a very specific threat: the kind of individualized profiling that is enabled by cross-context identifiers today. The goal of FLoC and other proposals is to avoid letting trackers access specific pieces of information that they can tie to specific people. As we’ve shown, FLoC may actually help trackers in many contexts. But even if Google is able to iterate on its design and prevent these risks, the harms of targeted advertising are not limited to violations of privacy. FLoC’s core objective is at odds with other civil liberties.
Many of the shortcomings and problems described in this paper are why most of the other browser makers have already announced that they will not support this proposal and will not be implementing it, and many platforms have raised their voice against it as well. Heck, even some regulators are realizing that this is a problematic proposal.
However, since Chrome is still the most dominant web browser around, with almost 50% of the market at hand, it is likely we will see this proposal becoming a reality in the coming years - or even months, as Google previously committed to deprecating third-party cookies by 2022.
And when it comes, as always, we will be waiting for it in open arms - and open ad-blockers.
FIN